1. 정보단위
비트(bit) : 0과 1을 표현하는 가장 작은 정보 단위
- n비트로 2&n가지의 정보 표현 가능
- 프로그램은 수많은 비트로 이루어져있음
- 비트보다 더 큰 단위를 사용(ex. 바이트, 킬로바이트...)
| 1바이트(byte) | 8 비트 |
| 1킬로바이트(KB) | 1,024 바이트 |
| 1메가바이트(MB) | 1,024 킬로바이트 |
| 1기가바이트(GB) | 1,024 메가바이트 |
| 1테라바이트(TB) | 1,024 기가바이 |
워드(word)
-CPU가 한번에 처리할 수 있는 정보의 크기 단위
2. 이진법
0과 1로 수를 표현하는 방법을 나타냄
1) 0과 1로 음수 표현하기 : 2의 보수
- (원래 정의) 어떤 수를 그보다 큰 2^n에서 뺀 값
EX. 11(2) 보다 큰 2^n( = 100(2))에서 11(2)를 뺀 값 -> 01(2)
- (더 쉬운 방법) 모든 0과 1을 뒤집고 1 더한 값
EX. 11(2) -> 00(2) + 1 = 01(2)
+ "-1011(2) 를 뜻하는 0101(2)과 십진수 5를 뜻하는 0101(2)는 똑같은데 어떻게 구분?"
=> CPU 내부 레지스터에 '플래그'라는 값이 있음. 그 '플래그'가 양수인지 음수인지 표식을 함.
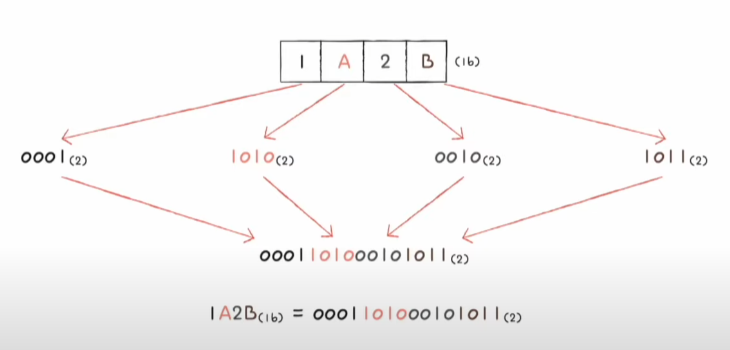
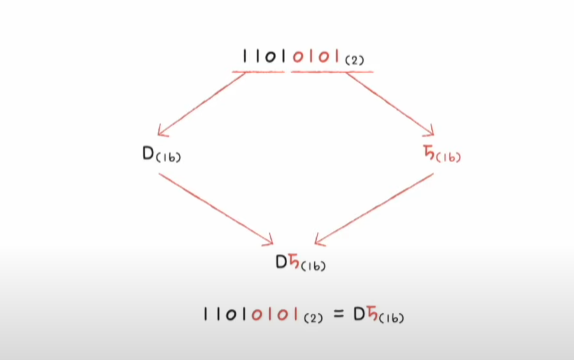
3. 십육진법
이진수와 십육진수(4비트) 와의 변환이 아주 간편하고 큰 수의 경우 이진수의 길이가 너무 길어지기 때문에 사용
4. 문자 집합과 인코딩
1) 문자 집합 : 컴퓨터가 이해할 수 있는 문자의 모음
2) 인코딩 : 코드화 하는 과정, 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정(문자 -> 0, 1)
3) 디코딩 : 코드를 해석하는 과정, 0과 1로 표현된 문자코드를 문자로 변환하는 과정(0, 1 -> 문자)
5. 아스키 코드
- 초창기 문자 집합 중 하나
- 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어 문자
- 7비트(128개의 문자)로 하나의 문자 표현(8비트 중 1비트는 오류 검출을 위해 사용되는 '패리티 비트')
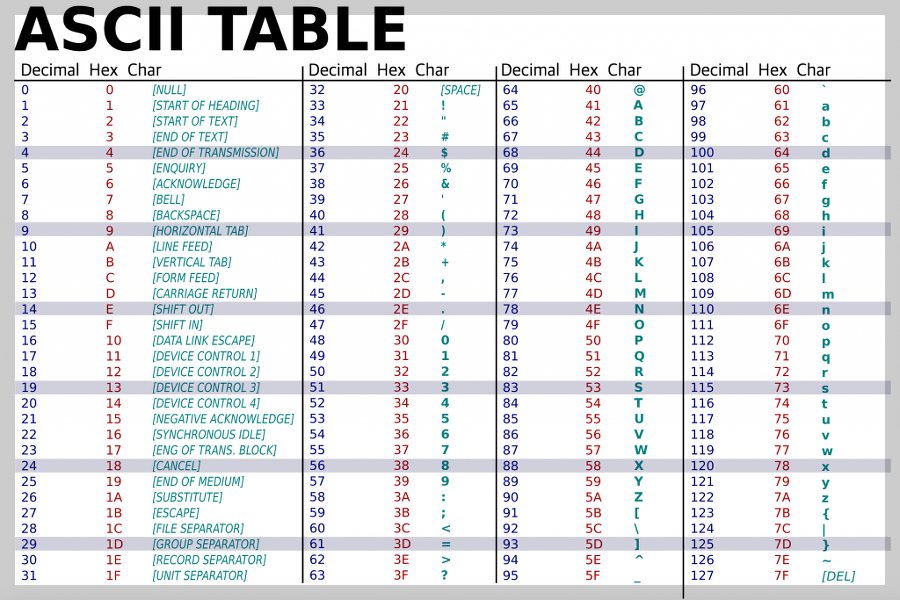
ex) A는 64로 인코딩, a는 97로 인코딩
- 한글을 포함한 다른 언어 문자, 다양한 특수 문자 표현 불가
6. 한글 인코딩 : 완성형 VS 조합형 인코딩
: 아스키 코드의 2^7로 표현할 수 없는 한글을 표현하기 위해 고안된 방법
- 초성, 중성, 종성의 조합으로 이루어진 한글
=> 완성형 인코딩 방식과 조합형 인코딩 방식이 존재
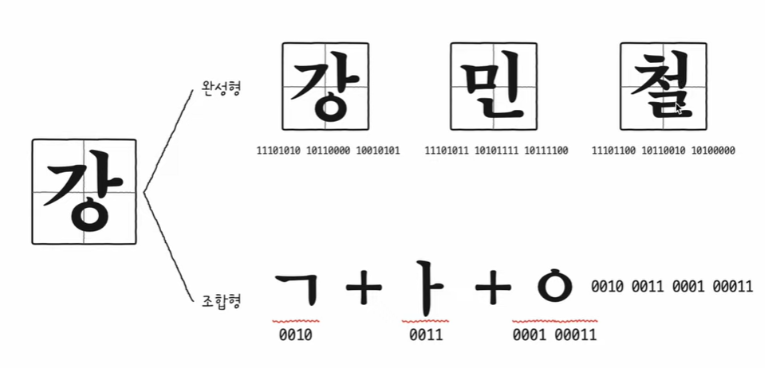
1) EUC-KR
- 완성형 인코딩
- 글자 하나하나에 2바이트(16비트) 크기의 코드 부여
-> 2바이트 == 16비트 == 4자리 십육진수
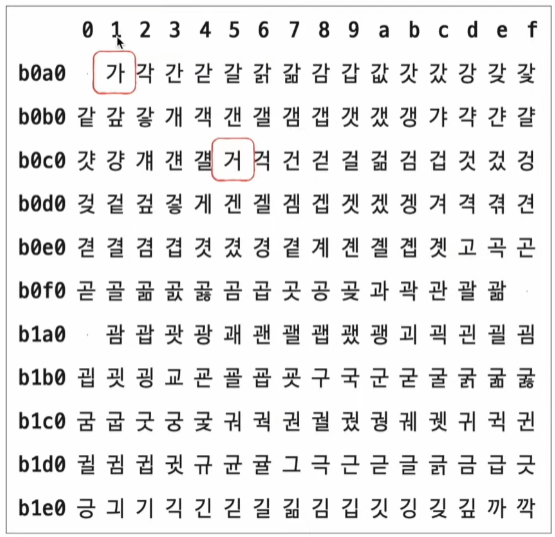
- 2300개의 한글 표현 가능(모든 한글을 표현하기에는 부족한 수)
2) 유니코드 문자 집합과 utf-8
- 통일된 문자집합
- 한글, 영어, 화살표와 같은 특수문자, 이모티콘
- 현대 문자 표현에 있어 매우 중요한 위치
'CS 공부' 카테고리의 다른 글
| [CS] {컴퓨터 구조} CPU 심화 (0) | 2025.04.09 |
|---|---|
| [CS] {컴퓨터 구조} CPU 구조 (0) | 2025.04.08 |
| [CS] {컴퓨터 구조} 언어&명령어 (0) | 2025.04.07 |
| [CS] {컴퓨터 구조} 컴퓨터 구조의 큰 그림 (0) | 2025.04.05 |
| [CS] 값타입과 참조타입 (Value Type & Reference Type) (0) | 2025.03.17 |